Xilinx Data Science Internship
I am currently a Data Science intern at Xilinx, a U.S. technology & semiconductor company (recently acquired by AMD) specializing in the development of adaptable and programmable logic devices. It is the company that invented the first commercial Field-Programmable Gate Array (FPGA) in 1985 and has recently shifted its focus towards ACAP (Adaptive Compute Acceleration Platform) technologies – the first line of product of which is called the Xilinx Versal ACAP. These are highly-integrated, multicore, compute platforms that are dynamically customizable to fit a wide range of software or hardware applications, whilst maintaining the compute performance of traditional ASIC (Application-Specific Integrated Circuits). Some of the primary applications of this new compute platform include:
- Machine Learning & AI in Data Centres
- 5G Wireless Communication
- Automotive Driving Assist (ADAS)
- Aerospace and Defense
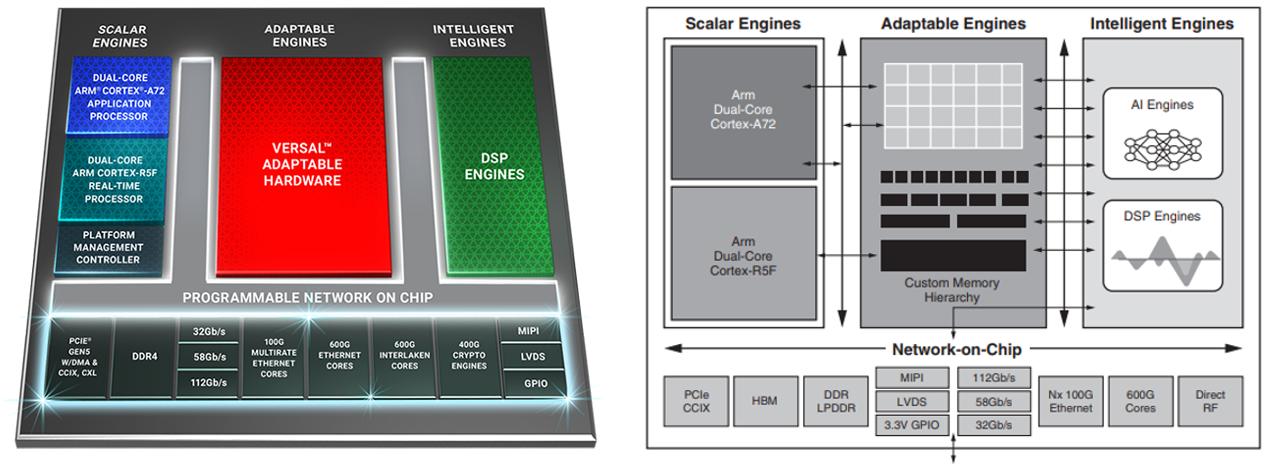
I work under the CSPG department (Communications and Signal Processing IP Group). This group is primarily focused on implementing efficient software libraries to perform core mathematical or signal-processing operations on the Xilinx Versal platform. This requires effective utilization of resources provided by the compute platform to achieve greatest throughput in the core DSP operations, e.g. through parallel (vectorized) processing, cascading AI Engines, MAC (Multiply Accumulate) operations, and efficient memory management. Under the CSPG group lies a cross-functional department known as the AIELib Group (Artificial Intelligence Engines Library), which is split into a further sub-branch known as DSPLib (Digital Signal Processing Library), the group I am currently assigned to. The figure below shows the high-level architecture of the Xilinx Versal ACAP, it consists of four main components:
- Scalar Engines: contains CPUs for scalar and sequential processing.
- Adaptable Engines: made up of programmable logic and memory cells to allow for device re-programmability.
- Intelligent engines: contains vector processors for parallel compute operations (e.g. for video processing, convolution operations).
- Network on Chip (NoC): connects all three engines through a memory-mapped interface layer with a bandwidth of up to 1TB/s.
As a Data Science intern, my responsibility has been in transforming the current data pipeline for the hardware testing of the Versal ACAP, including creating an automated analytics dashboard to harvest and display daily test runs, visualizing key performance metrics with Matplotlib, Plotly, and ChartJS, as well as data exploration with Jupyter Notebook. In addition, ML algorithms and models are used to perform commonality and causality analysis of the compilation or simulation error cases. These include the use of decision trees, PCA, DBSCAN clustering, and deep neural networks.